Current issue
Accepted manuscript
About the Journal
Scientific Council
Editorial Board
Regulatory and archival policy
Code of publishing ethics
Publisher
Information about the processing of personal data in relation to cookies and newsletter subscription
Archive
For Authors
For Reviewers
Contact
Reviewers
Annals reviewers in 2025
Annals reviewers in 2024
Annals reviewers in 2023
Annals reviewers in 2022
Annals reviewers in 2021
Annals reviewers in 2020
Annals reviewers in 2019
Annals reviewers in 2018
Annals reviewers in 2017
Annals reviewers in 2016
Annals reviewers in 2015
Annals reviewers in 2014
Annals reviewers in 2013
Annals reviewers in 2012
Links
Sklep Wydawnictwa SUM
Biblioteka Główna SUM
Śląski Uniwersytet Medyczny w Katowicach
Privacy policy
Accessibility statement
Reviewers
Annals reviewers in 2025
Annals reviewers in 2024
Annals reviewers in 2023
Annals reviewers in 2022
Annals reviewers in 2021
Annals reviewers in 2020
Annals reviewers in 2019
Annals reviewers in 2018
Annals reviewers in 2017
Annals reviewers in 2016
Annals reviewers in 2015
Annals reviewers in 2014
Annals reviewers in 2013
Annals reviewers in 2012

Performance of ChatGPT-3.5 and ChatGPT-4 in the field of specialist medical knowledge on National Specialization Exam in neurosurgery
1
Students’ Scientific Club, Department of Neurosurgery, Faculty of Medical Sciences in Katowice, Medical University of Silesia, Katowice, Poland
2
Unhyped, AI Growth Partner, Kraków, Poland
3
Department of Neurosurgery, Faculty of Medical Sciences in Katowice, Medical University of Silesia, Katowice, Poland
Corresponding author
Maciej Laskowski
Studenckie Koło Naukowe, Klinika Neurochirurgii, Wydział Nauk Medycznych w Katowicach, Śląski Uniwersytet Medyczny w Katowicach, ul. Medyków 14, 40-752 Katowice
Studenckie Koło Naukowe, Klinika Neurochirurgii, Wydział Nauk Medycznych w Katowicach, Śląski Uniwersytet Medyczny w Katowicach, ul. Medyków 14, 40-752 Katowice
Ann. Acad. Med. Siles. 2024;78:253-258

KEYWORDS
TOPICS
ABSTRACT
Introduction:
In recent times, there has been an increased number of published materials related to artificial intelligence (AI) in both the medical field, and specifically, in the domain of neurosurgery. Studies integrating AI into neurosurgical practice suggest an ongoing shift towards a greater dependence on AI-assisted tools for diagnostics, image analysis, and decision-making.
Material and methods:
The study evaluated the performance of ChatGPT-3.5 and ChatGPT-4 on a neurosurgery exam from Autumn 2017, which was the latest exam with officially provided answers on the Medical Examinations Center in Łódź, Poland (Centrum Egzaminów Medycznych – CEM) website. The passing score for the National Specialization Exam (Państwowy Egzamin Specjalizacyjny – PES) in Poland, as administered by CEM, is 56% of the valid questions. This exam, chosen from CEM, comprised 116 single-choice questions after eliminating four outdated questions. These questions were categorized into ten thematic groups based on the subjects they address. For data collection, both ChatGPT versions were briefed on the exam rules and asked to rate their confidence in each answer on a scale from 1 (definitely not sure) to 5 (definitely sure). All the interactions were conducted in Polish and were recorded.
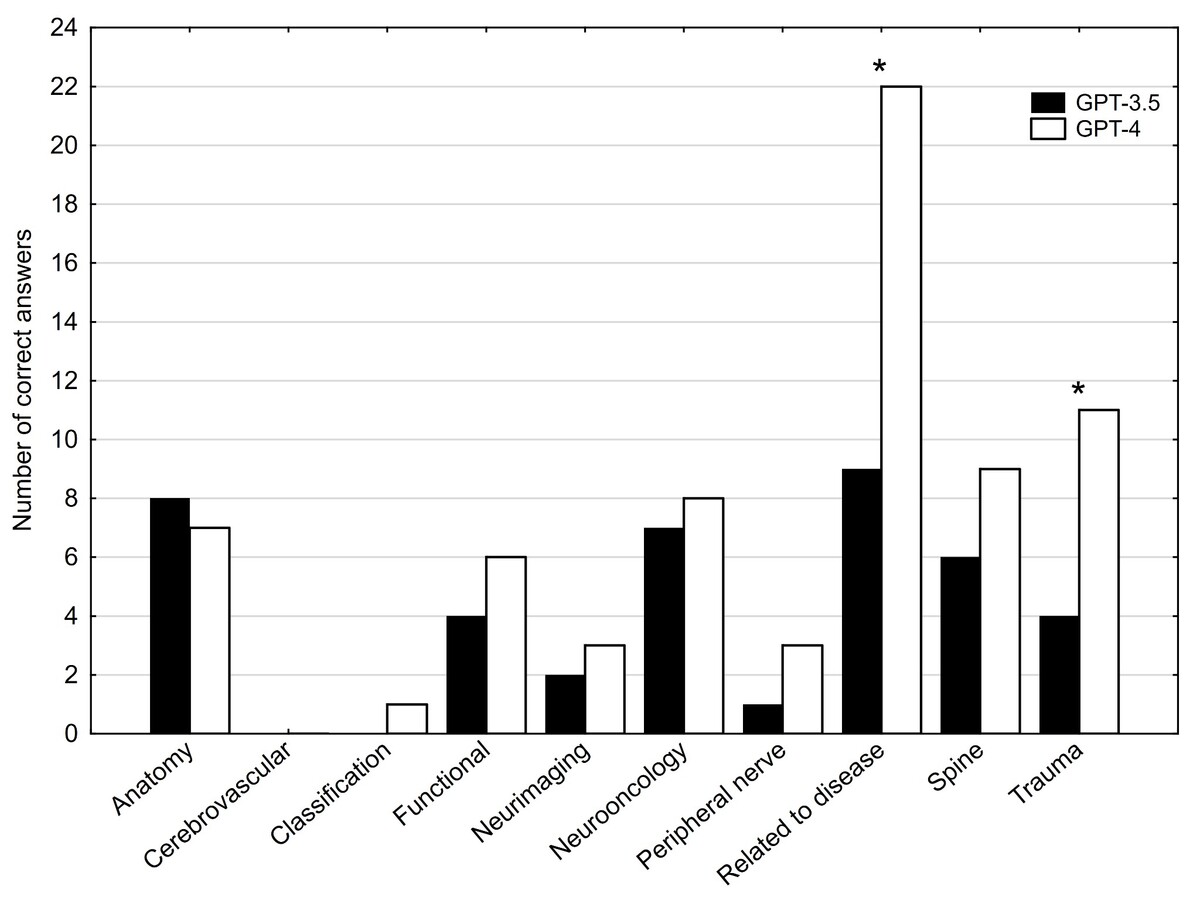
Results:
ChatGPT-4 significantly outperformed ChatGPT-3.5, showing a notable improvement with a 29.4% margin (p < 0.001). Unlike ChatGPT-3.5, ChatGPT-4 successfully reached the passing threshold for the PES. ChatGPT-3.5 and ChatGPT-4 had the same answers in 61 questions (52.58%), both were correct in 28 questions (24.14%), and were incorrect in 33 questions (28.45%).
Conclusions:
ChatGPT-4 shows improved accuracy over ChatGPT-3.5, likely due to advanced algorithms and a broader training dataset, highlighting its better grasp of complex neurosurgical concepts.
In recent times, there has been an increased number of published materials related to artificial intelligence (AI) in both the medical field, and specifically, in the domain of neurosurgery. Studies integrating AI into neurosurgical practice suggest an ongoing shift towards a greater dependence on AI-assisted tools for diagnostics, image analysis, and decision-making.
Material and methods:
The study evaluated the performance of ChatGPT-3.5 and ChatGPT-4 on a neurosurgery exam from Autumn 2017, which was the latest exam with officially provided answers on the Medical Examinations Center in Łódź, Poland (Centrum Egzaminów Medycznych – CEM) website. The passing score for the National Specialization Exam (Państwowy Egzamin Specjalizacyjny – PES) in Poland, as administered by CEM, is 56% of the valid questions. This exam, chosen from CEM, comprised 116 single-choice questions after eliminating four outdated questions. These questions were categorized into ten thematic groups based on the subjects they address. For data collection, both ChatGPT versions were briefed on the exam rules and asked to rate their confidence in each answer on a scale from 1 (definitely not sure) to 5 (definitely sure). All the interactions were conducted in Polish and were recorded.
Results:
ChatGPT-4 significantly outperformed ChatGPT-3.5, showing a notable improvement with a 29.4% margin (p < 0.001). Unlike ChatGPT-3.5, ChatGPT-4 successfully reached the passing threshold for the PES. ChatGPT-3.5 and ChatGPT-4 had the same answers in 61 questions (52.58%), both were correct in 28 questions (24.14%), and were incorrect in 33 questions (28.45%).
Conclusions:
ChatGPT-4 shows improved accuracy over ChatGPT-3.5, likely due to advanced algorithms and a broader training dataset, highlighting its better grasp of complex neurosurgical concepts.
REFERENCES (10)
1.
The Age of Artificial Intelligence: A brief history... Deloitte Malta, 01 Nov 2022 [online] https://www2.deloitte.com/mt/e... [accessed on 21 October 2023].
2.
Brockman G., Sutskever I., OpenAI. Introducing OpenAI. OpenAI, December 11, 2015 [online] https://openai.com/blog/introd... [accessed on 21 October 2023].
3.
Brown T., Mann B., Ryder N., Subbiah M., Kaplan J., Dhariwal P. et al. Language models are few-shot learners. OpenAI, May 28, 2020 [online] https://openai.com/research/la... [accessed on 21 October 2023].
4.
Bhasker S., Bruce D., Lamb J., Stein G. Tackling healthcare’s biggest burdens with generative AI. McKinsey & Company, July 10, 2023 [online] https://www.mckinsey.com/indus... [accessed on 21 October 2023].
5.
KMS Staff. Harnessing The Benefits of OpenAI in Healthcare. KMS Healthcare, June 29, 2023 [online] https://kms-healthcare.com/ben... [accessed on 21 October 2023].
6.
El-Hajj V.G., Gharios M., Edström E., Elmi-Terander A. Artificial intelligence in neurosurgery: A bibliometric analysis. World Neurosurg. 2023; 171: 152–158.e4, doi: 10.1016/j.wneu.2022.12.087.
7.
Danilov G.V., Shifrin M.A., Kotik K.V., Ishankulov T.A., Orlov Y.N., Kulikov A.S. et al. Artificial intelligence in neurosurgery: A systematic review using topic modeling. Part I: Major research areas. Sovrem. Tekhnologii Med. 2021; 12(5): 106–112, doi: 10.17691/stm2020.12.5.12.
8.
Ali R., Tang O.Y., Connolly I.D., Zadnik Sullivan P.L., Shin J.H., Fridley J.S. et al. Performance of ChatGPT and GPT-4 on neurosurgery written board examinations. Neurosurgery 2023; 93(6): 1353–1365, doi: 10.1227/neu.0000000000002632.
9.
Hopkins B.S., Nguyen V.N., Dallas J., Texakalidis P., Yang M., Renn A. et al. ChatGPT versus the neurosurgical written boards: a comparative analysis of artificial intelligence/machine learning performance on neurosurgical board-style questions. J. Neurosurg. 2023; 139(3): 904–911, doi: 10.3171/2023.2.JNS23419.
10.
Seghier M.L. ChatGPT: not all languages are equal. Nature 2023; 615(7951): 216, doi: 10.1038/d41586-023-00680-3.
CITATIONS (2):
1.
Assessment of the Ability of the ChatGPT-5 Model to Pass the Endocrinology Specialization Exam
Ada Latkowska, Piotr Sawina, Tomasz Dolata, Dawid Boczkowski, Aleksandra Wielochowska, Anna Kowalczyk, Michalina Loson-Kawalec, Dominika Radej, Wojciech Jaworski, Weronika Majchrowicz, Melania Olender, Julia Adamiak, Julia Sroczynska, Rania Suleiman, Julia Glinska, Patrycja Szczerbanowicz, Patrycja Dadynska
Cureus
Ada Latkowska, Piotr Sawina, Tomasz Dolata, Dawid Boczkowski, Aleksandra Wielochowska, Anna Kowalczyk, Michalina Loson-Kawalec, Dominika Radej, Wojciech Jaworski, Weronika Majchrowicz, Melania Olender, Julia Adamiak, Julia Sroczynska, Rania Suleiman, Julia Glinska, Patrycja Szczerbanowicz, Patrycja Dadynska
Cureus
2.
Artificial intelligence in anatomy education: a systematic review of ChatGPT’s effectiveness as a learning tool
Esin Erbek, Seval Çalışkan Pala, Güneş Bolatlı, Fatih Çavuş
Baylor University Medical Center Proceedings
Esin Erbek, Seval Çalışkan Pala, Güneş Bolatlı, Fatih Çavuş
Baylor University Medical Center Proceedings
| eISSN: | 1734-025X |

The Medical University of Silesia in Katowice, as the Operator of the annales.sum.edu.pl website, processes personal data collected when visiting the website. The function of obtaining information about Users and their behavior is carried out by voluntarily entered information in forms, saving cookies in end devices, as well as by collecting web server logs, which are in the possession of the website Operator. Data, including cookies, are used to provide services in accordance with the Privacy policy.
You can consent to the processing of data for these purposes, refuse consent or access more detailed information.
You can consent to the processing of data for these purposes, refuse consent or access more detailed information.