Bieżący numer
Artykuły zaakceptowane
O czasopiśmie
Rada Naukowa
Kolegium Redakcyjne
Polityka prawno-archiwizacyjna
Kodeks etyki publikacyjnej
Wydawca
Informacja o przetwarzaniu danych osobowych w ramach plików cookies oraz subskrypcji newslettera
Archiwum
Dla autorów
Dla recenzentów
Kontakt
Recenzenci
Recenzenci rocznika 2025
Recenzenci rocznika 2024
Recenzenci rocznika 2023
Recenzenci rocznika 2022
Recenzenci rocznika 2021
Recenzenci rocznika 2020
Recenzenci rocznika 2019
Recenzenci rocznika 2018
Recenzenci rocznika 2017
Recenzenci rocznika 2016
Recenzenci rocznika 2015
Recenzenci rocznika 2014
Recenzenci rocznika 2013
Recenzenci rocznika 2012
Polecamy
Śląski Uniwersytet Medyczny w Katowicach
Sklep Wydawnictw SUM
Biblioteka Główna SUM
Polityka prywatności
Deklaracja dostępności
Recenzenci
Recenzenci rocznika 2025
Recenzenci rocznika 2024
Recenzenci rocznika 2023
Recenzenci rocznika 2022
Recenzenci rocznika 2021
Recenzenci rocznika 2020
Recenzenci rocznika 2019
Recenzenci rocznika 2018
Recenzenci rocznika 2017
Recenzenci rocznika 2016
Recenzenci rocznika 2015
Recenzenci rocznika 2014
Recenzenci rocznika 2013
Recenzenci rocznika 2012

Porównanie efektywności ChatGPT-3.5 i ChatGPT-4 w zakresie specjalistycznej wiedzy medycznej na przykładzie Państwowego Egzaminu Specjalizacyjnego z neurochirurgii
1
Students’ Scientific Club, Department of Neurosurgery, Faculty of Medical Sciences in Katowice, Medical University of Silesia, Katowice, Poland
2
Unhyped, AI Growth Partner, Kraków, Poland
3
Department of Neurosurgery, Faculty of Medical Sciences in Katowice, Medical University of Silesia, Katowice, Poland
Autor do korespondencji
Maciej Laskowski
Studenckie Koło Naukowe, Klinika Neurochirurgii, Wydział Nauk Medycznych w Katowicach, Śląski Uniwersytet Medyczny w Katowicach, ul. Medyków 14, 40-752 Katowice
Studenckie Koło Naukowe, Klinika Neurochirurgii, Wydział Nauk Medycznych w Katowicach, Śląski Uniwersytet Medyczny w Katowicach, ul. Medyków 14, 40-752 Katowice
Ann. Acad. Med. Siles. 2024;78:253-258

SŁOWA KLUCZOWE
DZIEDZINY
STRESZCZENIE
WPROWADZENIE::
W ostatnim czasie obserwuje się wzrost liczby opublikowanych artykułów dotyczących sztucznej inteligencji w dziedzinie medycyny, szczególnie w obszarze neurochirurgii. Badania dotyczące integracji sztucznej inteligencji z praktyką neurochirurgiczną wskazują na postępującą zmianę w kierunku szerszego wykorzystania narzędzi wspomaganych sztuczną inteligencją w diagnostyce, analizie obrazu i podejmowaniu decyzji.
MATERIAŁ I METODY::
W badaniu oceniono efektywność ChatGPT-3.5 i ChatGPT-4 na Państwowym Egzaminie Specjalizacyjnym (PES) z neurochirurgii przeprowadzonym jesienią 2017 r., który w czasie przeprowadzania badania był najnowszym dostępnym na stronie Centrum Egzaminów Medycznych (CEM) egzaminem z oficjalnie udostępnionymi odpowiedziami. Próg zdawalności egzaminu specjalizacyjnego wynosi 56% poprawnych odpowiedzi. Egzamin składał się ze 116 pytań jednokrotnego wyboru, po wyeliminowaniu czterech z uwagi na ich niezgodność z aktualną wiedzą. Ze względu na poruszane zagadnienia pytania podzielono na dziesięć grup tematycznych. Na potrzeby gromadzenia danych obie wersje ChatGPT zostały poinformowane o zasadach egzaminu i poproszone o ocenę stopnia pewności co do każdej odpowiedzi w skali od 1 (zdecydowanie niepewny) do 5 (zdecydowanie pewny). Wszystkie interakcje odbywały się w języku polskim i były rejestrowane.
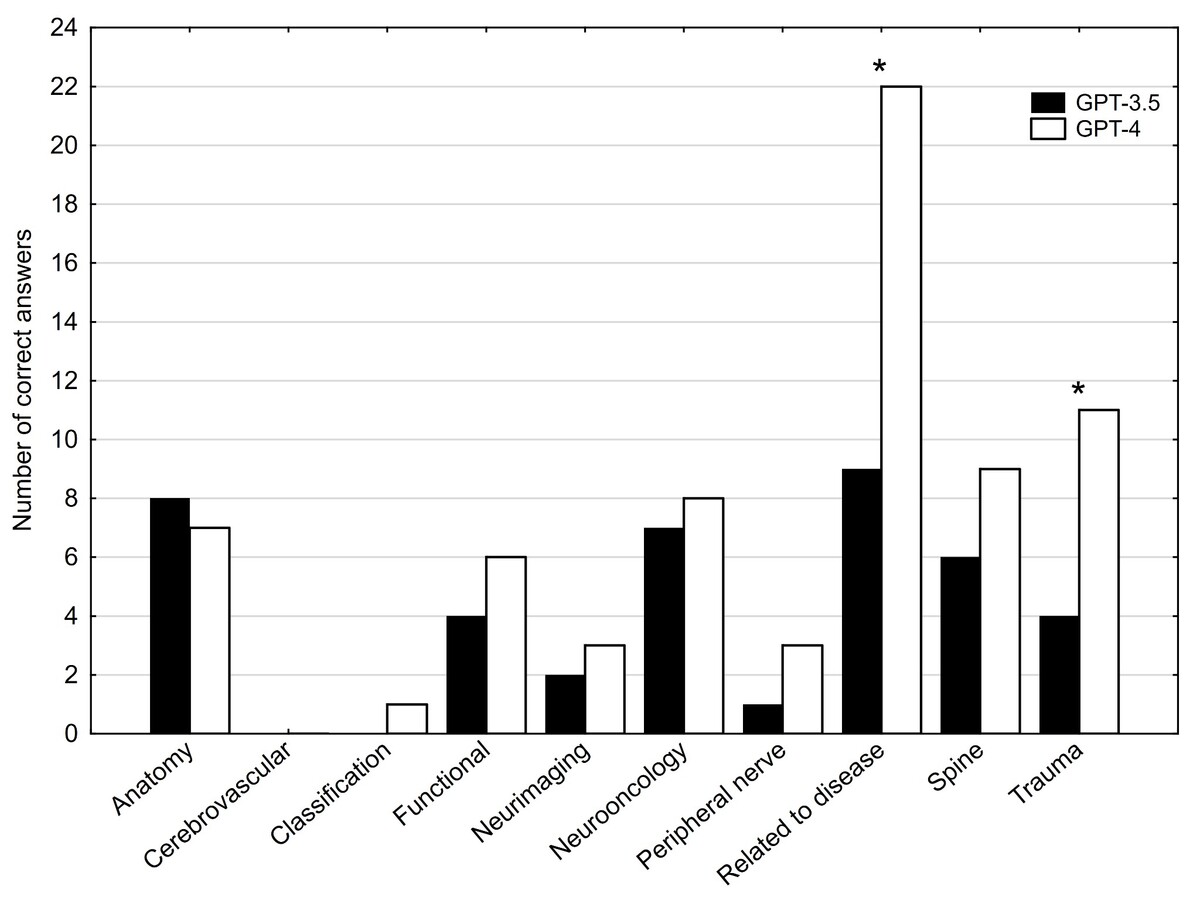
WYNIKI::
ChatGPT-4 wyraźnie przewyższył ChatGPT-3.5 z różnicą wynoszącą 29,4% (p < 0,001). W przeciwieństwie do ChatGPT-3.5, ChatGPT-4 z sukcesem osiągnął próg zdawalności dla PES. W testach ChatGPT-3.5 i ChatGPT-4 odpowiedzi były takie same w 61 pytaniach (52,58%), w obu przypadkach były poprawne w 28 pytaniach (24,14%) i niepoprawne w 33 pytaniach (28,45%).
WNIOSKI::
ChatGPT-4 osiąga większą poprawność w udzielanych odpowiedziach w porównaniu z ChatGPT-3.5, prawdopodobnie dzięki zaawansowanym algorytmom i szerszemu zbiorowi danych treningowych, co podkreśla lepsze zrozumienie złożonych koncepcji neurochirurgicznych.
W ostatnim czasie obserwuje się wzrost liczby opublikowanych artykułów dotyczących sztucznej inteligencji w dziedzinie medycyny, szczególnie w obszarze neurochirurgii. Badania dotyczące integracji sztucznej inteligencji z praktyką neurochirurgiczną wskazują na postępującą zmianę w kierunku szerszego wykorzystania narzędzi wspomaganych sztuczną inteligencją w diagnostyce, analizie obrazu i podejmowaniu decyzji.
MATERIAŁ I METODY::
W badaniu oceniono efektywność ChatGPT-3.5 i ChatGPT-4 na Państwowym Egzaminie Specjalizacyjnym (PES) z neurochirurgii przeprowadzonym jesienią 2017 r., który w czasie przeprowadzania badania był najnowszym dostępnym na stronie Centrum Egzaminów Medycznych (CEM) egzaminem z oficjalnie udostępnionymi odpowiedziami. Próg zdawalności egzaminu specjalizacyjnego wynosi 56% poprawnych odpowiedzi. Egzamin składał się ze 116 pytań jednokrotnego wyboru, po wyeliminowaniu czterech z uwagi na ich niezgodność z aktualną wiedzą. Ze względu na poruszane zagadnienia pytania podzielono na dziesięć grup tematycznych. Na potrzeby gromadzenia danych obie wersje ChatGPT zostały poinformowane o zasadach egzaminu i poproszone o ocenę stopnia pewności co do każdej odpowiedzi w skali od 1 (zdecydowanie niepewny) do 5 (zdecydowanie pewny). Wszystkie interakcje odbywały się w języku polskim i były rejestrowane.
WYNIKI::
ChatGPT-4 wyraźnie przewyższył ChatGPT-3.5 z różnicą wynoszącą 29,4% (p < 0,001). W przeciwieństwie do ChatGPT-3.5, ChatGPT-4 z sukcesem osiągnął próg zdawalności dla PES. W testach ChatGPT-3.5 i ChatGPT-4 odpowiedzi były takie same w 61 pytaniach (52,58%), w obu przypadkach były poprawne w 28 pytaniach (24,14%) i niepoprawne w 33 pytaniach (28,45%).
WNIOSKI::
ChatGPT-4 osiąga większą poprawność w udzielanych odpowiedziach w porównaniu z ChatGPT-3.5, prawdopodobnie dzięki zaawansowanym algorytmom i szerszemu zbiorowi danych treningowych, co podkreśla lepsze zrozumienie złożonych koncepcji neurochirurgicznych.
REFERENCJE (10)
1.
The Age of Artificial Intelligence: A brief history... Deloitte Malta, 01 Nov 2022 [online] https://www2.deloitte.com/mt/e... [accessed on 21 October 2023].
2.
Brockman G., Sutskever I., OpenAI. Introducing OpenAI. OpenAI, December 11, 2015 [online] https://openai.com/blog/introd... [accessed on 21 October 2023].
3.
Brown T., Mann B., Ryder N., Subbiah M., Kaplan J., Dhariwal P. et al. Language models are few-shot learners. OpenAI, May 28, 2020 [online] https://openai.com/research/la... [accessed on 21 October 2023].
4.
Bhasker S., Bruce D., Lamb J., Stein G. Tackling healthcare’s biggest burdens with generative AI. McKinsey & Company, July 10, 2023 [online] https://www.mckinsey.com/indus... [accessed on 21 October 2023].
5.
KMS Staff. Harnessing The Benefits of OpenAI in Healthcare. KMS Healthcare, June 29, 2023 [online] https://kms-healthcare.com/ben... [accessed on 21 October 2023].
6.
El-Hajj V.G., Gharios M., Edström E., Elmi-Terander A. Artificial intelligence in neurosurgery: A bibliometric analysis. World Neurosurg. 2023; 171: 152–158.e4, doi: 10.1016/j.wneu.2022.12.087.
7.
Danilov G.V., Shifrin M.A., Kotik K.V., Ishankulov T.A., Orlov Y.N., Kulikov A.S. et al. Artificial intelligence in neurosurgery: A systematic review using topic modeling. Part I: Major research areas. Sovrem. Tekhnologii Med. 2021; 12(5): 106–112, doi: 10.17691/stm2020.12.5.12.
8.
Ali R., Tang O.Y., Connolly I.D., Zadnik Sullivan P.L., Shin J.H., Fridley J.S. et al. Performance of ChatGPT and GPT-4 on neurosurgery written board examinations. Neurosurgery 2023; 93(6): 1353–1365, doi: 10.1227/neu.0000000000002632.
9.
Hopkins B.S., Nguyen V.N., Dallas J., Texakalidis P., Yang M., Renn A. et al. ChatGPT versus the neurosurgical written boards: a comparative analysis of artificial intelligence/machine learning performance on neurosurgical board-style questions. J. Neurosurg. 2023; 139(3): 904–911, doi: 10.3171/2023.2.JNS23419.
10.
Seghier M.L. ChatGPT: not all languages are equal. Nature 2023; 615(7951): 216, doi: 10.1038/d41586-023-00680-3.
CYTOWANIA (2):
1.
Assessment of the Ability of the ChatGPT-5 Model to Pass the Endocrinology Specialization Exam
Ada Latkowska, Piotr Sawina, Tomasz Dolata, Dawid Boczkowski, Aleksandra Wielochowska, Anna Kowalczyk, Michalina Loson-Kawalec, Dominika Radej, Wojciech Jaworski, Weronika Majchrowicz, Melania Olender, Julia Adamiak, Julia Sroczynska, Rania Suleiman, Julia Glinska, Patrycja Szczerbanowicz, Patrycja Dadynska
Cureus
Ada Latkowska, Piotr Sawina, Tomasz Dolata, Dawid Boczkowski, Aleksandra Wielochowska, Anna Kowalczyk, Michalina Loson-Kawalec, Dominika Radej, Wojciech Jaworski, Weronika Majchrowicz, Melania Olender, Julia Adamiak, Julia Sroczynska, Rania Suleiman, Julia Glinska, Patrycja Szczerbanowicz, Patrycja Dadynska
Cureus
2.
Artificial intelligence in anatomy education: a systematic review of ChatGPT’s effectiveness as a learning tool
Esin Erbek, Seval Çalışkan Pala, Güneş Bolatlı, Fatih Çavuş
Baylor University Medical Center Proceedings
Esin Erbek, Seval Çalışkan Pala, Güneş Bolatlı, Fatih Çavuş
Baylor University Medical Center Proceedings
Udostępnij
| eISSN: | 1734-025X |

Śląski Uniwersytet Medyczny w Katowicach, jako Operator Serwisu annales.sum.edu.pl, przetwarza dane osobowe zbierane podczas odwiedzania Serwisu. Realizacja funkcji pozyskiwania informacji o Użytkownikach i ich zachowaniu odbywa się poprzez dobrowolnie wprowadzone w formularzach informacje, zapisywanie w urządzeniach końcowych plików cookies (tzw. ciasteczka), a także poprzez gromadzenie logów serwera www, będącego w posiadaniu Operatora Serwisu. Dane, w tym pliki cookies, wykorzystywane są w celu realizacji usług zgodnie z Polityką prywatności.
Możesz wyrazić zgodę na przetwarzanie danych w tych celach, odmówić zgody lub uzyskać dostęp do bardziej szczegółowych informacji.
Możesz wyrazić zgodę na przetwarzanie danych w tych celach, odmówić zgody lub uzyskać dostęp do bardziej szczegółowych informacji.