Current issue
Accepted manuscript
About the Journal
Scientific Council
Editorial Board
Regulatory and archival policy
Code of publishing ethics
Publisher
Information about the processing of personal data in relation to cookies and newsletter subscription
Archive
For Authors
For Reviewers
Contact
Reviewers
Annals reviewers in 2025
Annals reviewers in 2024
Annals reviewers in 2023
Annals reviewers in 2022
Annals reviewers in 2021
Annals reviewers in 2020
Annals reviewers in 2019
Annals reviewers in 2018
Annals reviewers in 2017
Annals reviewers in 2016
Annals reviewers in 2015
Annals reviewers in 2014
Annals reviewers in 2013
Annals reviewers in 2012
Links
Sklep Wydawnictwa SUM
Biblioteka Główna SUM
Śląski Uniwersytet Medyczny w Katowicach
Privacy policy
Accessibility statement
Reviewers
Annals reviewers in 2025
Annals reviewers in 2024
Annals reviewers in 2023
Annals reviewers in 2022
Annals reviewers in 2021
Annals reviewers in 2020
Annals reviewers in 2019
Annals reviewers in 2018
Annals reviewers in 2017
Annals reviewers in 2016
Annals reviewers in 2015
Annals reviewers in 2014
Annals reviewers in 2013
Annals reviewers in 2012

ChatGPT – a tool for assisted studying or a source of misleading medical information? AI performance on Polish Medical Final Examination
1
Department of Infectious Diseases and Hepatology, Faculty of Medical Sciences in Zabrze, Medical University of Silesia, Katowice, Poland
2
Department of Medical and Molecular Biology, Faculty of Medical Sciences in Zabrze, Medical University of Silesia, Katowice, Poland
3
Department of Psychiatry, Faculty of Medical Sciences in Zabrze, Medical University of Silesia, Katowice, Poland
Corresponding author
Karol Żmudka
Katedra i Klinika Chorób Zakaźnych i Hepatologii, Górnośląskie Centrum Medyczne im. prof. Leszka Gieca SUM, ul. Ziołowa 45/47, 40-635 Katowice
Katedra i Klinika Chorób Zakaźnych i Hepatologii, Górnośląskie Centrum Medyczne im. prof. Leszka Gieca SUM, ul. Ziołowa 45/47, 40-635 Katowice
Ann. Acad. Med. Siles. 2024;78:94-103

KEYWORDS
TOPICS
ABSTRACT
Introduction:
ChatGPT is a language model created by OpenAI that can engage in human-like conversations and generate text based on the input it receives. The aim of the study was to assess the overall performance of ChatGPT on the Polish Medical Final Examination (Lekarski Egzamin Końcowy – LEK) the factors influencing the percentage of correct answers. Secondly, investigate the capabilities of chatbot to provide explanations was examined.
Material and methods:
We entered 591 questions with distractors from the LEK database into ChatGPT (version 13th February – 14th March). We compared the results with the answer key and analyzed the provided explanation for logical justification. For the correct answers we analyzed the logical consistency of the explanation, while for the incorrect answers, the ability to provide a correction was observed. Selected factors were analyzed for an influence on the chatbot’s performance.
Results:
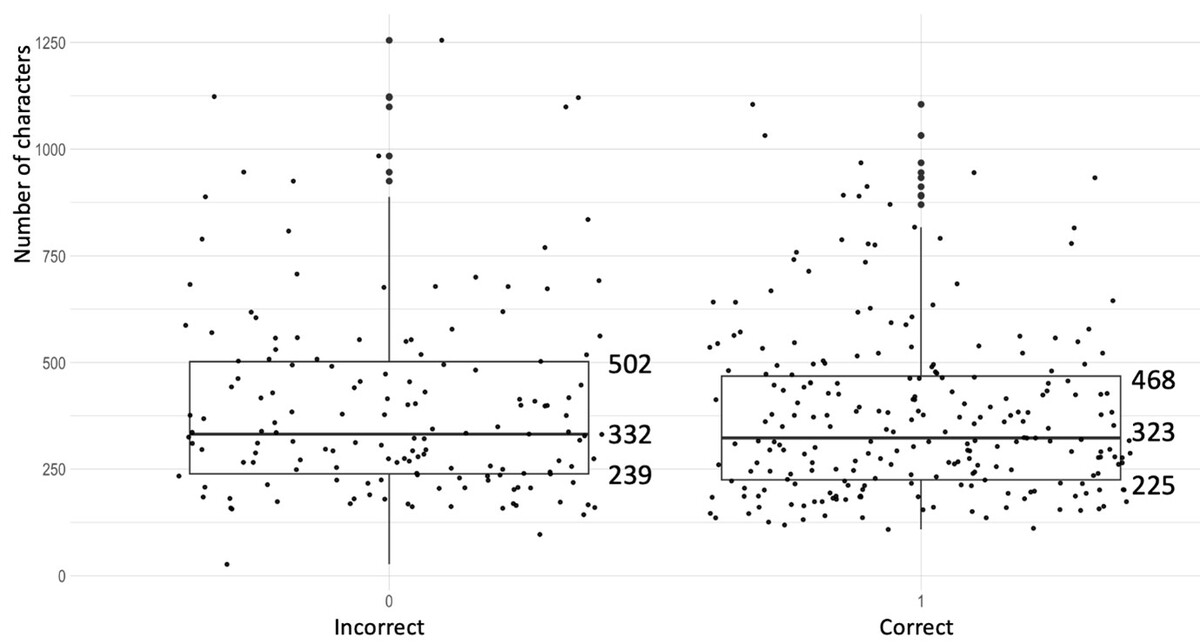
ChatGPT achieved impressive scores of 58.16%, 60.91% and 67.86% allowing it pass the official threshold of 56% in all instances. For the properly answered questions, more than 70% were backed by a logically coherent explanation. In the case of the wrongly answered questions the chatbot provided a seemingly correct explanation for false information in 66% of the cases. Factors such as logical construction (p < 0.05) and difficulty (p < 0.05) had an influence on the overall score, meanwhile the length (p = 0.46) and language (p = 0.14) did not.
Conclusions:
Although achieving a sufficient score to pass LEK, ChatGPT in many cases provides misleading information backed by a seemingly compelling explanation. The chatbot can be especially misleading for non-medical users as compared to a web search because it can provide instant compelling explanations. Thus, if used improperly, it could pose a danger to public health. This makes it a problematic recommendation for assisted studying.
ChatGPT is a language model created by OpenAI that can engage in human-like conversations and generate text based on the input it receives. The aim of the study was to assess the overall performance of ChatGPT on the Polish Medical Final Examination (Lekarski Egzamin Końcowy – LEK) the factors influencing the percentage of correct answers. Secondly, investigate the capabilities of chatbot to provide explanations was examined.
Material and methods:
We entered 591 questions with distractors from the LEK database into ChatGPT (version 13th February – 14th March). We compared the results with the answer key and analyzed the provided explanation for logical justification. For the correct answers we analyzed the logical consistency of the explanation, while for the incorrect answers, the ability to provide a correction was observed. Selected factors were analyzed for an influence on the chatbot’s performance.
Results:
ChatGPT achieved impressive scores of 58.16%, 60.91% and 67.86% allowing it pass the official threshold of 56% in all instances. For the properly answered questions, more than 70% were backed by a logically coherent explanation. In the case of the wrongly answered questions the chatbot provided a seemingly correct explanation for false information in 66% of the cases. Factors such as logical construction (p < 0.05) and difficulty (p < 0.05) had an influence on the overall score, meanwhile the length (p = 0.46) and language (p = 0.14) did not.
Conclusions:
Although achieving a sufficient score to pass LEK, ChatGPT in many cases provides misleading information backed by a seemingly compelling explanation. The chatbot can be especially misleading for non-medical users as compared to a web search because it can provide instant compelling explanations. Thus, if used improperly, it could pose a danger to public health. This makes it a problematic recommendation for assisted studying.
REFERENCES (19)
1.
Nori H., King N., McKinney S.M., Carignan D., Horvitz E. Capabilities of GPT-4 on medical challenge problems [Internet]. arXiv; 2023 [cited 2023 Jul 30]. Available from: http://arxiv.org/abs/2303.1337....
2.
Newton P.M., Xiromeriti M. ChatGPT performance on MCQ exams in higher education: A pragmatic scoping review [Internet]. EdArXiv; 2023 Feb [cited 2023 Jul 6]. Available from: https://osf.io/sytu3.
3.
Kung T.H., Cheatham M., Medenilla A., Sillos C., De Leon L., Elepaño C. et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digit. Health 2023; 2(2): e0000198, doi: 10.1371/journal.pdig.0000198.
4.
Sabry Abdel-Messih M., Kamel Boulos M.N. ChatGPT in clinical toxicology. JMIR Med. Educ. 2023; 9: e46876, doi: 10.2196/46876.
5.
Ali R., Tang O.Y., Connolly I.D., Zadnik Sullivan P.L., Shin J.H., Fridley J.S. et al. Performance of ChatGPT and GPT-4 on neurosurgery written board examinations. Neurosurgery 2023; 93(6): 1353–1365, doi: 10.1227/neu.0000000000002632.
6.
opis_statystyk.pdf [Internet]. Centrum Egzaminów Medycznych; [cited 2023 Nov 17]. Available from: https://www.cem.edu.pl/aktualn....
7.
Kelley T.L. The selection of upper and lower groups for the validation of test items. J. Educ. Psych. 1939; 30(1): 17–24.
8.
Takagi S., Watari T., Erabi A., Sakaguchi K. Performance of GPT-3.5 and GPT-4 on the Japanese Medical Licensing Examination: comparison study. JMIR Med. Educ. 2023; 9: e48002, doi: 10.2196/48002.
9.
Rosoł M., Gąsior J.S., Łaba J., Korzeniewski K., Młyńczak M. Evalua-tion of the performance of GPT-3.5 and GPT-4 on the Medical Final Examination [Internet]. medRxiv; 2023 [cited 2023 Jul 1]. doi: 10.1101/2023.06.04.23290939. Available from: https://www.medrxiv.org/conten....
10.
Gilson A., Safranek C., Huang T., Socrates V., Chi L., Taylor R.A. et al. How does ChatGPT perform on the Medical Licensing Exams? The implications of large language models for medical education and knowledge assessment [Internet]. medRxiv; 2022 [cited 2023 Jul 3]. doi: 10.1101/2022.12.23.22283901. Available from: https://www.medrxiv.org/conten....
11.
OpenAI. GPT-4 technical report [Internet]. arXiv; 2023 [cited 2023 Jul 1]. Available from: http://arxiv.org/abs/2303.0877....
12.
Kasai J., Kasai Y., Sakaguchi K., Yamada Y., Radev D. Evaluating GPT-4 and ChatGPT on Japanese Medical Licensing Examinations [Internet]. arXiv; 2023 [cited 2023 Jul 1]. Available from: http://arxiv.org/abs/2303.1802....
13.
Mihalache A., Popovic M.M., Muni R.H. Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment. JAMA Ophthalmol. 2023; 141(6): 589–597, doi: 10.1001/jamaophthalmol.2023.1144.
14.
Powell J., Inglis N., Ronnie J., Large S. The characteristics and motivations of online health information seekers: cross-sectional survey and qualitative interview study. J. Med. Internet Res. 2011; 13(1): e20, doi: 10.2196/jmir.1600.
15.
Sallam M. ChatGPT utility in healthcare education, research, and practice: systematic review on the promising perspectives and valid concerns. Healthcare 2023; 11(6): 887, doi: 10.3390/healthcare11060887.
16.
Hopkins A.M., Logan J.M., Kichenadasse G., Sorich M.J. Artificial intelligence chatbots will revolutionize how cancer patients access information: ChatGPT represents a paradigm-shift. JNCI Cancer Spectr. 2023; 7(2): pkad010, doi: 10.1093/jncics/pkad010.
17.
Bujnowska-Fedak M.M. Trends in the use of the Internet for health purposes in Poland. BMC Public Health 2015; 15: 194, doi: 10.1186/s12889-015-1473-3.
18.
Borji A. A categorical archive of ChatGPT failures [Internet]. arXiv; 2023 [cited 2023 Jul 3]. Available from: http://arxiv.org/abs/2302.0349....
19.
Zuccon G., Koopman B. Dr ChatGPT, tell me what I want to hear: How prompt knowledge impacts health answer correctness [Internet]. arXiv; 2023 [cited 2023 Jul 2]. Available from: http://arxiv.org/abs/2302.1379....
CITATIONS (1):
Share
RELATED ARTICLE
| eISSN: | 1734-025X |

The Medical University of Silesia in Katowice, as the Operator of the annales.sum.edu.pl website, processes personal data collected when visiting the website. The function of obtaining information about Users and their behavior is carried out by voluntarily entered information in forms, saving cookies in end devices, as well as by collecting web server logs, which are in the possession of the website Operator. Data, including cookies, are used to provide services in accordance with the Privacy policy.
You can consent to the processing of data for these purposes, refuse consent or access more detailed information.
You can consent to the processing of data for these purposes, refuse consent or access more detailed information.