Bieżący numer
Artykuły zaakceptowane
O czasopiśmie
Rada Naukowa
Kolegium Redakcyjne
Polityka prawno-archiwizacyjna
Kodeks etyki publikacyjnej
Wydawca
Informacja o przetwarzaniu danych osobowych w ramach plików cookies oraz subskrypcji newslettera
Archiwum
Dla autorów
Dla recenzentów
Kontakt
Recenzenci
Recenzenci rocznika 2025
Recenzenci rocznika 2024
Recenzenci rocznika 2023
Recenzenci rocznika 2022
Recenzenci rocznika 2021
Recenzenci rocznika 2020
Recenzenci rocznika 2019
Recenzenci rocznika 2018
Recenzenci rocznika 2017
Recenzenci rocznika 2016
Recenzenci rocznika 2015
Recenzenci rocznika 2014
Recenzenci rocznika 2013
Recenzenci rocznika 2012
Polecamy
Śląski Uniwersytet Medyczny w Katowicach
Sklep Wydawnictw SUM
Biblioteka Główna SUM
Polityka prywatności
Deklaracja dostępności
Recenzenci
Recenzenci rocznika 2025
Recenzenci rocznika 2024
Recenzenci rocznika 2023
Recenzenci rocznika 2022
Recenzenci rocznika 2021
Recenzenci rocznika 2020
Recenzenci rocznika 2019
Recenzenci rocznika 2018
Recenzenci rocznika 2017
Recenzenci rocznika 2016
Recenzenci rocznika 2015
Recenzenci rocznika 2014
Recenzenci rocznika 2013
Recenzenci rocznika 2012

ChatGPT – pomoc naukowa przyszłości czy źródło fałszywych informacji? Analiza odpowiedzi sztucznej inteligencji na przykładzie zadań Lekarskiego Egzaminu Końcowego
1
Department of Infectious Diseases and Hepatology, Faculty of Medical Sciences in Zabrze, Medical University of Silesia, Katowice, Poland
2
Department of Medical and Molecular Biology, Faculty of Medical Sciences in Zabrze, Medical University of Silesia, Katowice, Poland
3
Department of Psychiatry, Faculty of Medical Sciences in Zabrze, Medical University of Silesia, Katowice, Poland
Autor do korespondencji
Karol Żmudka
Katedra i Klinika Chorób Zakaźnych i Hepatologii, Górnośląskie Centrum Medyczne im. prof. Leszka Gieca SUM, ul. Ziołowa 45/47, 40-635 Katowice
Katedra i Klinika Chorób Zakaźnych i Hepatologii, Górnośląskie Centrum Medyczne im. prof. Leszka Gieca SUM, ul. Ziołowa 45/47, 40-635 Katowice
Ann. Acad. Med. Siles. 2024;78:94-103

SŁOWA KLUCZOWE
DZIEDZINY
STRESZCZENIE
Wstęp:
ChatGPT jest modelem językowym stworzonym przez OpenAI, który może udzielać odpowiedzi na zapytania użytkownika, generując tekst na podstawie otrzymanych danych. Celem pracy była ocena wyników działania ChatGPT na polskim Lekarskim Egzaminie Końcowym (LEK) oraz czynników wpływających na odsetek prawidłowych odpowiedzi. Ponadto zbadano zdolność chatbota do podawania poprawnego i wnikliwego wyjaśnienia.
Materiał i metody:
Wprowadzono 591 pytań z dystraktorami z bazy LEK do interfejsu ChatGPT (wersja 13 lutego – 14 marca). Porównano wyniki z kluczem odpowiedzi i przeanalizowano podane wyjaśnienia pod kątem logicznego uzasadnienia. Dla poprawnych odpowiedzi przeanalizowano spójność logiczną wyjaśnienia, natomiast w przypadku odpowiedzi błędnej obserwowano zdolność do poprawy. Wybrane czynniki zostały przeanalizowane pod kątem wpływu na zdolność chatbota do udzielenia poprawnej odpowiedzi.
Wyniki:
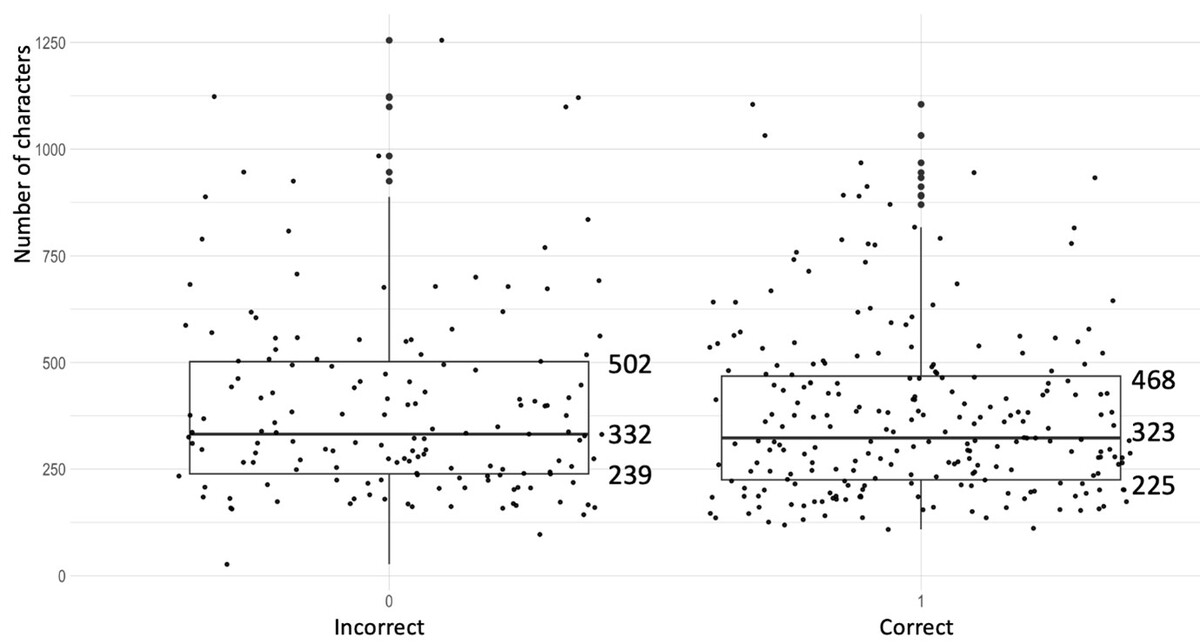
ChatGPT osiągnął imponujące wyniki poprawnych odpowiedzi na poziomie: 58,16%, 60,91% i 67,86%, przekraczając oficjalny próg 56% w trzech ostatnich egzaminach. W przypadku poprawnie udzielonych odpowiedzi ponad 70% pytań zostało popartych logicznie spójnym wyjaśnieniem. W przypadku błędnych odpowiedzi w 66% przypadków chatbot podał pozornie poprawne wyjaśnienie dla nieprawidłowych odpowiedzi. Czynniki takie jak konstrukcja logiczna (p < 0,05) i wskaźnik trudności zadania (p < 0,05) miały wpływ na ogólną ocenę, podczas gdy liczba znaków (p = 0,46) i język (p = 0,14) takiego wpływu nie miały.
Wnioski:
Mimo iż ChatGPT osiągnął wystarczającą liczbę punktów, aby zaliczyć LEK, w wielu przypadkach podawał wprowadzające w błąd informacje poparte pozornie przekonującym wyjaśnieniem. Chatboty mogą być szczególnym zagrożeniem dla użytkownika niemającego wiedzy medycznej, ponieważ w porównaniu z wyszukiwarką internetową dają natychmiastowe, przekonujące wyjaśnienie, co może stanowić zagrożenie dla zdrowia publicznego. Z tych samych przyczyn ChatGPT powinien być ostrożnie stosowany jako pomoc naukowa.
ChatGPT jest modelem językowym stworzonym przez OpenAI, który może udzielać odpowiedzi na zapytania użytkownika, generując tekst na podstawie otrzymanych danych. Celem pracy była ocena wyników działania ChatGPT na polskim Lekarskim Egzaminie Końcowym (LEK) oraz czynników wpływających na odsetek prawidłowych odpowiedzi. Ponadto zbadano zdolność chatbota do podawania poprawnego i wnikliwego wyjaśnienia.
Materiał i metody:
Wprowadzono 591 pytań z dystraktorami z bazy LEK do interfejsu ChatGPT (wersja 13 lutego – 14 marca). Porównano wyniki z kluczem odpowiedzi i przeanalizowano podane wyjaśnienia pod kątem logicznego uzasadnienia. Dla poprawnych odpowiedzi przeanalizowano spójność logiczną wyjaśnienia, natomiast w przypadku odpowiedzi błędnej obserwowano zdolność do poprawy. Wybrane czynniki zostały przeanalizowane pod kątem wpływu na zdolność chatbota do udzielenia poprawnej odpowiedzi.
Wyniki:
ChatGPT osiągnął imponujące wyniki poprawnych odpowiedzi na poziomie: 58,16%, 60,91% i 67,86%, przekraczając oficjalny próg 56% w trzech ostatnich egzaminach. W przypadku poprawnie udzielonych odpowiedzi ponad 70% pytań zostało popartych logicznie spójnym wyjaśnieniem. W przypadku błędnych odpowiedzi w 66% przypadków chatbot podał pozornie poprawne wyjaśnienie dla nieprawidłowych odpowiedzi. Czynniki takie jak konstrukcja logiczna (p < 0,05) i wskaźnik trudności zadania (p < 0,05) miały wpływ na ogólną ocenę, podczas gdy liczba znaków (p = 0,46) i język (p = 0,14) takiego wpływu nie miały.
Wnioski:
Mimo iż ChatGPT osiągnął wystarczającą liczbę punktów, aby zaliczyć LEK, w wielu przypadkach podawał wprowadzające w błąd informacje poparte pozornie przekonującym wyjaśnieniem. Chatboty mogą być szczególnym zagrożeniem dla użytkownika niemającego wiedzy medycznej, ponieważ w porównaniu z wyszukiwarką internetową dają natychmiastowe, przekonujące wyjaśnienie, co może stanowić zagrożenie dla zdrowia publicznego. Z tych samych przyczyn ChatGPT powinien być ostrożnie stosowany jako pomoc naukowa.
REFERENCJE (19)
1.
Nori H., King N., McKinney S.M., Carignan D., Horvitz E. Capabilities of GPT-4 on medical challenge problems [Internet]. arXiv; 2023 [cited 2023 Jul 30]. Available from: http://arxiv.org/abs/2303.1337....
2.
Newton P.M., Xiromeriti M. ChatGPT performance on MCQ exams in higher education: A pragmatic scoping review [Internet]. EdArXiv; 2023 Feb [cited 2023 Jul 6]. Available from: https://osf.io/sytu3.
3.
Kung T.H., Cheatham M., Medenilla A., Sillos C., De Leon L., Elepaño C. et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digit. Health 2023; 2(2): e0000198, doi: 10.1371/journal.pdig.0000198.
4.
Sabry Abdel-Messih M., Kamel Boulos M.N. ChatGPT in clinical toxicology. JMIR Med. Educ. 2023; 9: e46876, doi: 10.2196/46876.
5.
Ali R., Tang O.Y., Connolly I.D., Zadnik Sullivan P.L., Shin J.H., Fridley J.S. et al. Performance of ChatGPT and GPT-4 on neurosurgery written board examinations. Neurosurgery 2023; 93(6): 1353–1365, doi: 10.1227/neu.0000000000002632.
6.
opis_statystyk.pdf [Internet]. Centrum Egzaminów Medycznych; [cited 2023 Nov 17]. Available from: https://www.cem.edu.pl/aktualn....
7.
Kelley T.L. The selection of upper and lower groups for the validation of test items. J. Educ. Psych. 1939; 30(1): 17–24.
8.
Takagi S., Watari T., Erabi A., Sakaguchi K. Performance of GPT-3.5 and GPT-4 on the Japanese Medical Licensing Examination: comparison study. JMIR Med. Educ. 2023; 9: e48002, doi: 10.2196/48002.
9.
Rosoł M., Gąsior J.S., Łaba J., Korzeniewski K., Młyńczak M. Evalua-tion of the performance of GPT-3.5 and GPT-4 on the Medical Final Examination [Internet]. medRxiv; 2023 [cited 2023 Jul 1]. doi: 10.1101/2023.06.04.23290939. Available from: https://www.medrxiv.org/conten....
10.
Gilson A., Safranek C., Huang T., Socrates V., Chi L., Taylor R.A. et al. How does ChatGPT perform on the Medical Licensing Exams? The implications of large language models for medical education and knowledge assessment [Internet]. medRxiv; 2022 [cited 2023 Jul 3]. doi: 10.1101/2022.12.23.22283901. Available from: https://www.medrxiv.org/conten....
11.
OpenAI. GPT-4 technical report [Internet]. arXiv; 2023 [cited 2023 Jul 1]. Available from: http://arxiv.org/abs/2303.0877....
12.
Kasai J., Kasai Y., Sakaguchi K., Yamada Y., Radev D. Evaluating GPT-4 and ChatGPT on Japanese Medical Licensing Examinations [Internet]. arXiv; 2023 [cited 2023 Jul 1]. Available from: http://arxiv.org/abs/2303.1802....
13.
Mihalache A., Popovic M.M., Muni R.H. Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment. JAMA Ophthalmol. 2023; 141(6): 589–597, doi: 10.1001/jamaophthalmol.2023.1144.
14.
Powell J., Inglis N., Ronnie J., Large S. The characteristics and motivations of online health information seekers: cross-sectional survey and qualitative interview study. J. Med. Internet Res. 2011; 13(1): e20, doi: 10.2196/jmir.1600.
15.
Sallam M. ChatGPT utility in healthcare education, research, and practice: systematic review on the promising perspectives and valid concerns. Healthcare 2023; 11(6): 887, doi: 10.3390/healthcare11060887.
16.
Hopkins A.M., Logan J.M., Kichenadasse G., Sorich M.J. Artificial intelligence chatbots will revolutionize how cancer patients access information: ChatGPT represents a paradigm-shift. JNCI Cancer Spectr. 2023; 7(2): pkad010, doi: 10.1093/jncics/pkad010.
17.
Bujnowska-Fedak M.M. Trends in the use of the Internet for health purposes in Poland. BMC Public Health 2015; 15: 194, doi: 10.1186/s12889-015-1473-3.
18.
Borji A. A categorical archive of ChatGPT failures [Internet]. arXiv; 2023 [cited 2023 Jul 3]. Available from: http://arxiv.org/abs/2302.0349....
19.
Zuccon G., Koopman B. Dr ChatGPT, tell me what I want to hear: How prompt knowledge impacts health answer correctness [Internet]. arXiv; 2023 [cited 2023 Jul 2]. Available from: http://arxiv.org/abs/2302.1379....
CYTOWANIA (1):
Udostępnij
ARTYKUŁ POWIĄZANY
| eISSN: | 1734-025X |

Śląski Uniwersytet Medyczny w Katowicach, jako Operator Serwisu annales.sum.edu.pl, przetwarza dane osobowe zbierane podczas odwiedzania Serwisu. Realizacja funkcji pozyskiwania informacji o Użytkownikach i ich zachowaniu odbywa się poprzez dobrowolnie wprowadzone w formularzach informacje, zapisywanie w urządzeniach końcowych plików cookies (tzw. ciasteczka), a także poprzez gromadzenie logów serwera www, będącego w posiadaniu Operatora Serwisu. Dane, w tym pliki cookies, wykorzystywane są w celu realizacji usług zgodnie z Polityką prywatności.
Możesz wyrazić zgodę na przetwarzanie danych w tych celach, odmówić zgody lub uzyskać dostęp do bardziej szczegółowych informacji.
Możesz wyrazić zgodę na przetwarzanie danych w tych celach, odmówić zgody lub uzyskać dostęp do bardziej szczegółowych informacji.